最近上课也上到爬虫了,我想起了 @GamerNoTitle 做过一个爬一言的BLOG:Hitokoto-Spider 一言库爬虫开发日记 (据说这是他的第一个Python实战)
于是我觉得我的第一个实战也可以来搞一个(当然抄代码是不可能的)
参考了一下一言的官方开发者文档,我就敲代码了
项目地址:https://github.com/2X-ercha/Hitokoto-Spider
利用一言官方API爬取
文档中接口说明如下:
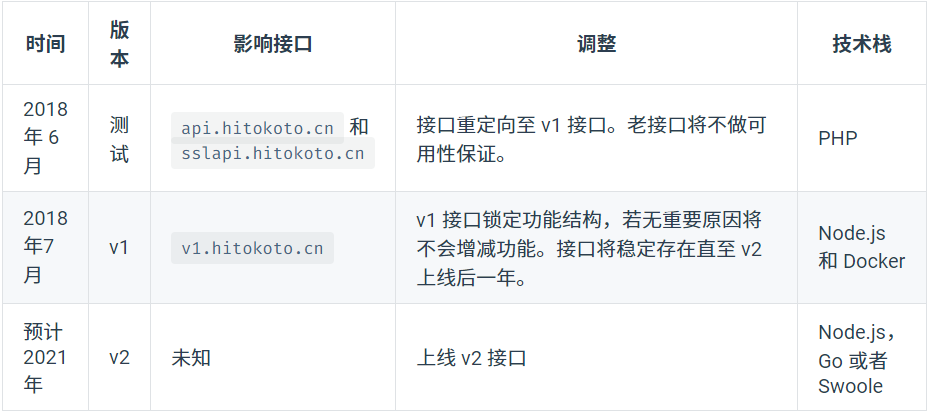

因为有先看了大佬的博客,知道爬下来是个json(这玩意比html好解析多了)
所以我看了看官方json的说明:
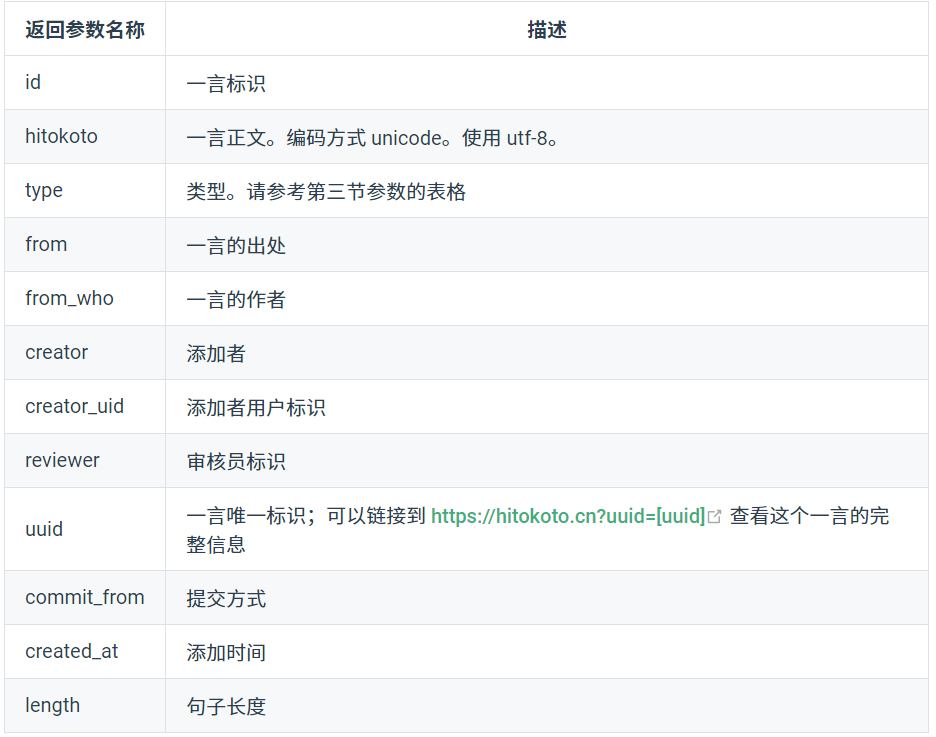
有些信息是我不需要的,我就不管他了
保留一下信息:"id", "sort", "hitokoto", "from", "from_who", "creator", "created_at"
好了,我们开始爬了
利用requests库爬取数据
def Hitokoto_spider():
ids=np.zeros(10000,dtype=bool)
res=r.get("https://v1.hitokoto.cn",timeout=60)
data=res.json()
if not ids[data["id"]]:
print("{}:\t{}".format(data["id"],data["hitokoto"]))
ids[data["id"]]=True
|
用ids数组来判断是否抓取过(因为我知道一言的总数不多,数组大小我就只设了10000)
然后爬着爬着,就错误了???
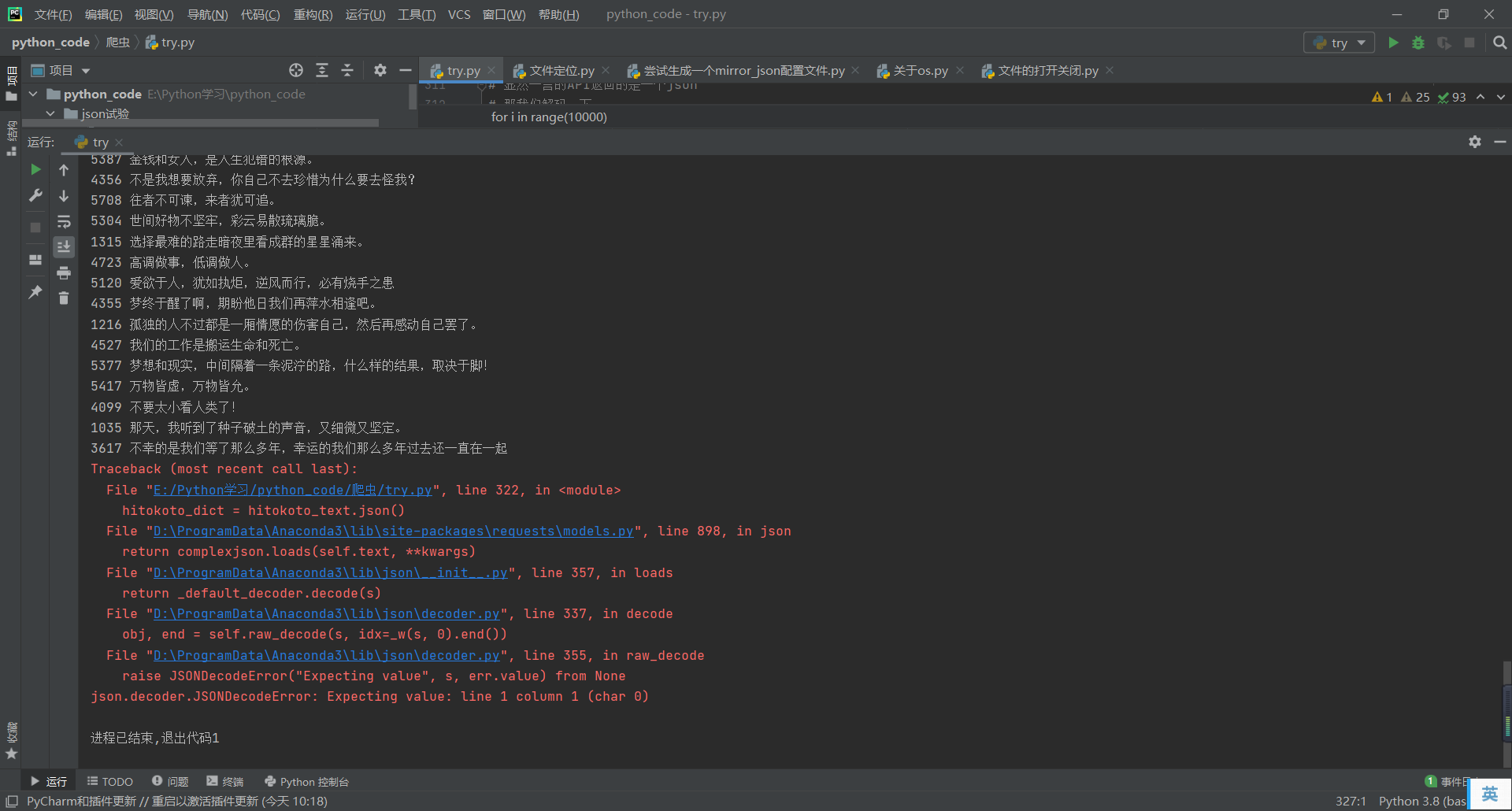
我又爬了一次,让他输出错误的状态码,他给我返回了513
这是啥子嘛!
于是我加入了个判断状态码,状态码一错就休息一下重新再爬
if res.status_code == 513:
time.sleep(30)
return Hitokoto_spider()
|
然后。。。出门了一趟,回来你给我看这个???
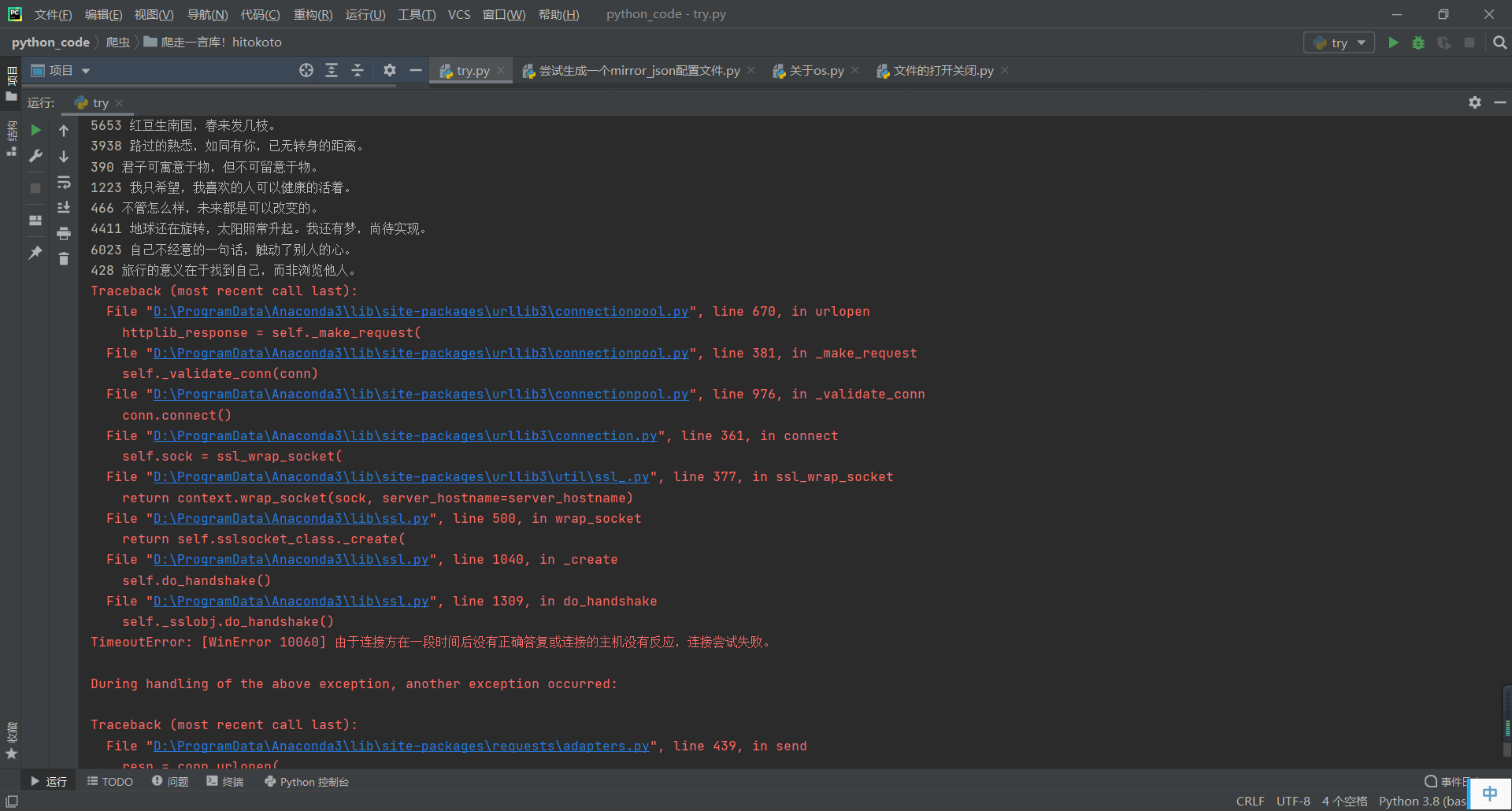
原来我电脑休眠了
然后我把电脑的休眠调掉,把上面的 res.status_code == 513 改成 res.status_code != 200
开始爬!
在他爬的时候,我加入了json文件支持
由于本人不太喜欢手动创建,又怕我不小心勿删了文件导致程序出错
所以我给了个默认创建(所以这段代码比较长)
def read_config():
try:
if not os.path.exists("./data"):
os.mkdir("./data")
with open('./data/_config.json') as config_js:
config = js.load(config_js)
return config
except IOError:
with open('./data/_config.json', 'w', encoding='utf-8') as config:
configs = {
"path": "./data/Hitokoto.csv",
"times": 3000,
"delay": 2,
"timeout": 60,
"from": True,
"from_who": True,
"creator": False,
"created_at": False
}
a = js.dumps(configs, indent=4, separators=(',', ':'))
config.write(a)
return read_config()
|
之后看到的一些调用就变成这样子了
cfg = read_config()
print(cfg["hitokoto"])
|
然后要把爬下来的一言存下来
我又加了一点点代码
def create_csv():
cfg=read_config()
with open(cfg["path"],"w+",newline="",encoding="utf8") as file:
csv_file = csv.writer(file)
head = ["id", "sort", "hitokoto", "from", "from_who", "creator", "created_at"]
csv_file.writerow(head)
def append_csv(inputs):
cfg = read_config()
with open(cfg["path"],"a+",newline='',encoding="utf8") as file:
csv_file = csv.writer(file)
data = [inputs]
csv_file.writerows(data)
|
同时对爬虫的代码进行一点点修改
def Hitokoto_spider():
cfg=read_config()
res=r.get("https://v1.hitokoto.cn",timeout=cfg["timeout"])
if res.status_code != 200:
time.sleep(cfg["delay"])
return Hitokoto_spider()
data=res.json()
if not ids[data["id"]]:
print("{}:\t{}".format(data["id"],data["hitokoto"]))
ids[data["id"]]=True
sorts = ["Animation", "Comics", "Games", "Literature", "Original", "Internet",
"Other", "Film and television", "Poetry", "Netease", "Philosophy", "Smart"]
x=ord(data["type"])-97
if 0<=x<12: sort = sorts[x]
else: sort = "Animation"
inputs = [data["id"], sort, data["hitokoto"], data["from"], data["from_who"], data["creator"], data["created_at"]]
append_csv(inputs)
|
之前的爬取错误也出来了
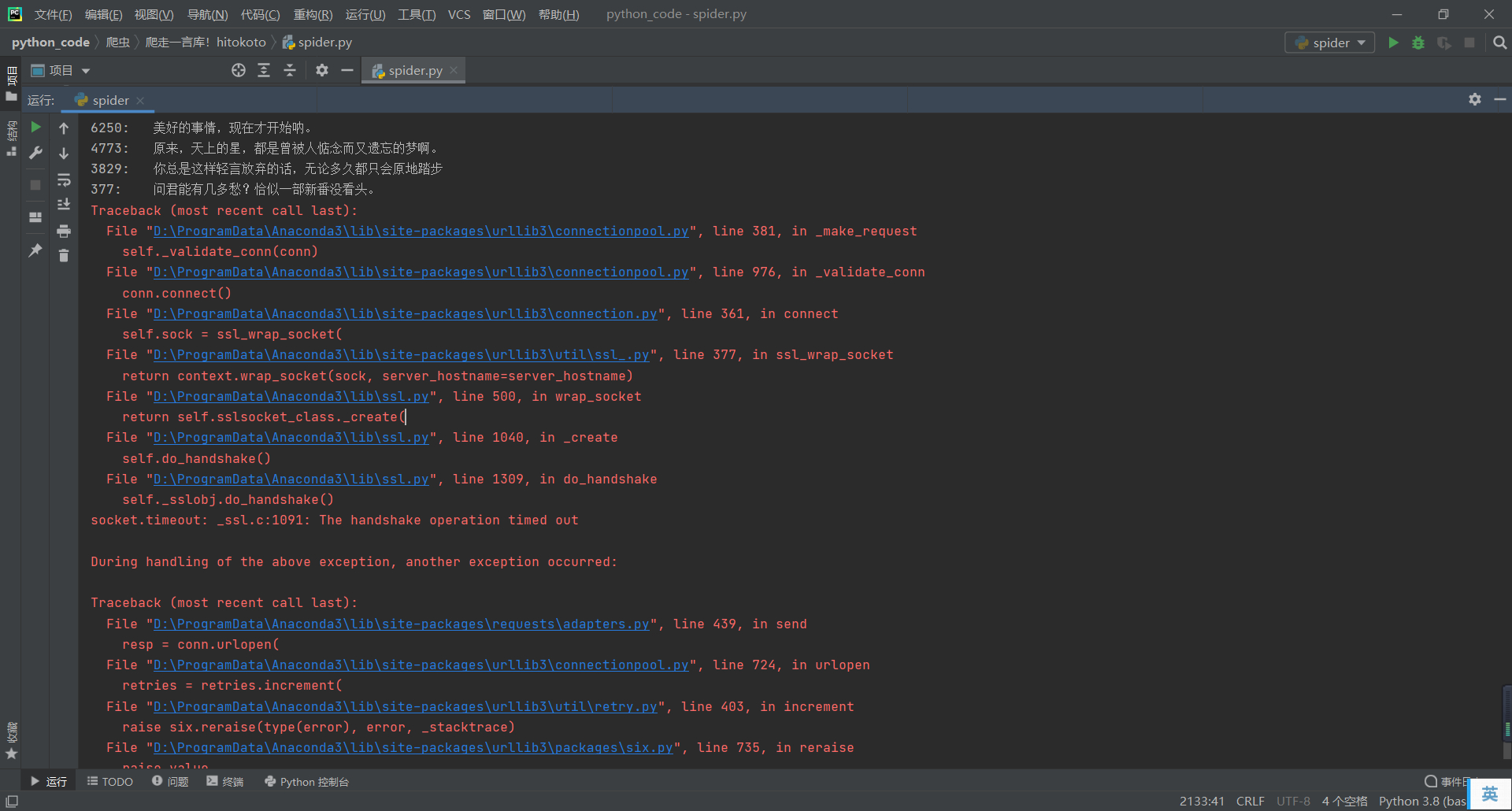
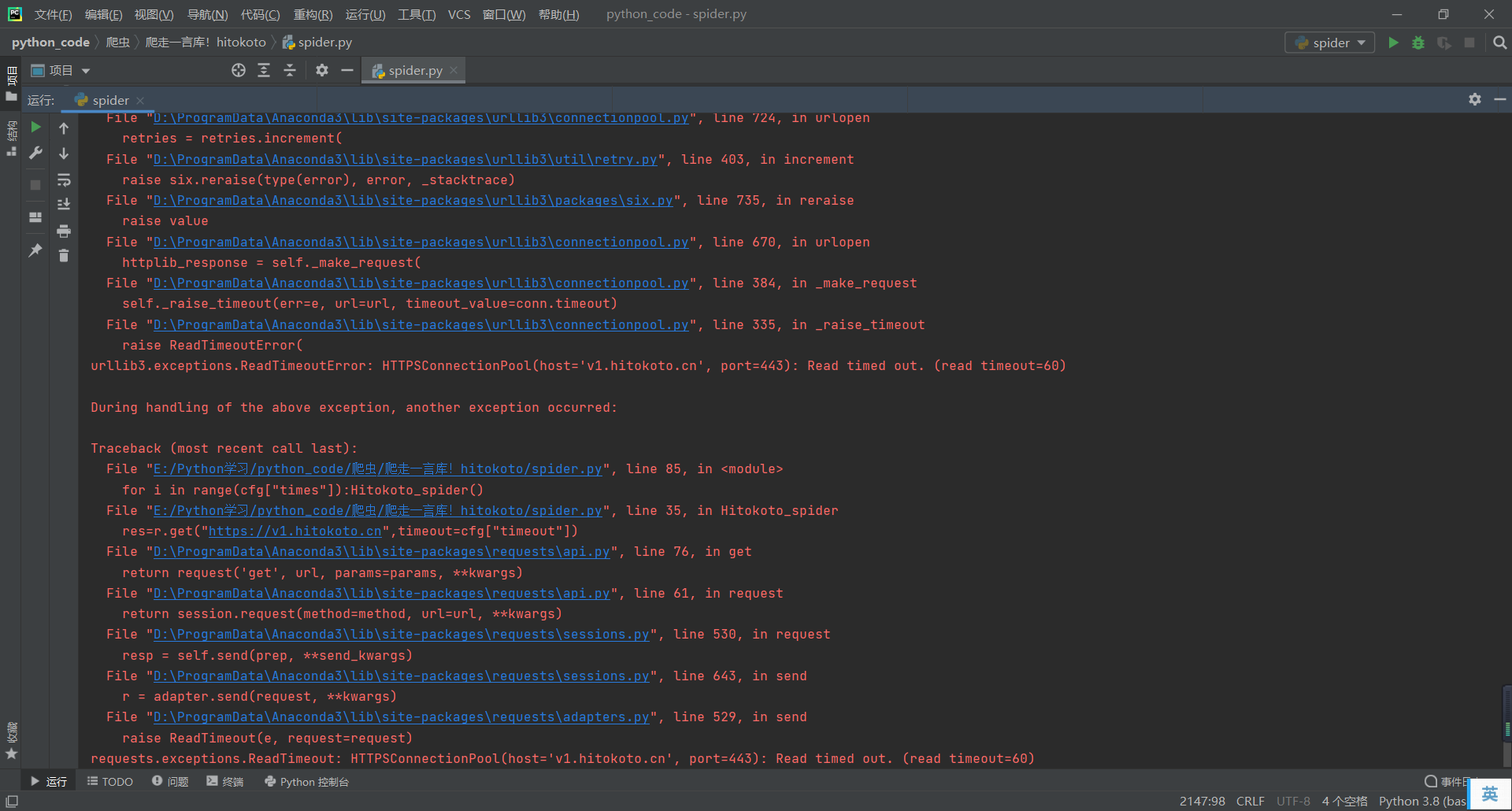
我原本以为是 TimeoutError
加入了 except TimeoutError 后仍然发生了这样的问题
不管了,不管他什么问题,通通 except !
def Hitokoto_spider():
try:
cfg=read_config()
res=r.get("https://v1.hitokoto.cn",timeout=cfg["timeout"])
if res.status_code != 200:
time.sleep(cfg["delay"])
return Hitokoto_spider()
data=res.json()
if not ids[data["id"]]:
print("{}:\t{}".format(data["id"],data["hitokoto"]))
ids[data["id"]]=True
sorts = ["Animation", "Comics", "Games", "Literature", "Original", "Internet",
"Other", "Film and television", "Poetry", "Netease", "Philosophy", "Smart"]
x=ord(data["type"])-97
if 0<=x<12: sort = sorts[x]
else: sort = "Animation"
inputs = [data["id"], sort, data["hitokoto"], data["from"], data["from_who"], data["creator"], data["created_at"]]
append_csv(inputs)
except:
time.sleep(60)
Hitokoto_spider()
|
加入重复爬取
上面的代码只能让我单次爬取,每次爬取都会覆盖原先的文档
所以我把ids数组存了下来
def save_ids():
ids_file = "./data/ids.npy"
np.save(ids_file, ids)
def load_ids():
ids_file = "./data/ids.npy"
ids=np.load(ids_file)
return ids
|
在每次爬取前load,在爬取结束时save就可以啦!
数据整理
因为API接口的随机性,爬到的id并不是按顺序爬到的,所以得进行排序
def sort_Hitokoto():
cfg = read_config()
Hitokoto_data = pd.read_csv(cfg["path"])
Hitokoto_data = Hitokoto_data.sort_values("id")
Hitokoto_data.to_csv(cfg["path"],index=False)
|
最终的结果长这样啦!

这个项目还没做完,之后可能会做API和GUI,以及非官方的一言收集
官方API的随机性使得我现在的爬取基本上是爬不到的
官方一言库共4396条
2020.12.21,30000次爬取,获取3323条
2020.12.22,30000次爬取,获取29条
2020.12.23,40000次爬取,获取0条
慢慢爬吧
附:直接利用官网的具体id爬取
这个方法是解析网站 https://hitokoto.cn/?id=1 的html来爬去
网站地址后面id接的数字对应的就是相应一言的id,范围:1-6623
优点:避免随机,一次爬取就可爬取全部
缺点:只能爬到id,一言文本和作者
直接贴代码,有兴趣可以自己复制去试试
注:id不连续
import requests
from bs4 import BeautifulSoup
import csv
import time
headers = {
"Cookie": "arccount62298=c; arccount62019=c",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66"
}
with open("hitokoto.csv","w+",newline="",encoding="utf8") as file:
csv_file = csv.writer(file)
head = ["id", "hitokoto", "from"]
csv_file.writerow(head)
for id in range(1,6624):
time.sleep(2)
try:
url = "https://hitokoto.cn/?id=" + str(id)
html = requests.get(url, headers = headers, timeout = 60)
soup = BeautifulSoup(html.text, "html.parser")
hitokoto = soup.find(id = "hitokoto_text")
author = soup.find(id = "hitokoto_author")
with open("hitokoto.csv","a+",newline='',encoding="utf8") as file:
csv_file = csv.writer(file)
data = [[id,hitokoto.string,author.string[3:]]]
print("{}\t{}\t{}".format(id,hitokoto.string,author.string[3:]))
csv_file.writerows(data)
except:continue
|
(我就是用这个方式获取到了一言库的数据总数)

